12
ArchiveBox
🗃 L'archive Web auto-hébergée open source.Prend l'historique du navigateur / signets / Pocket / Pinboard / etc., Enregistre HTML, JS, PDF, médias, et plus encore.
- Gratuite
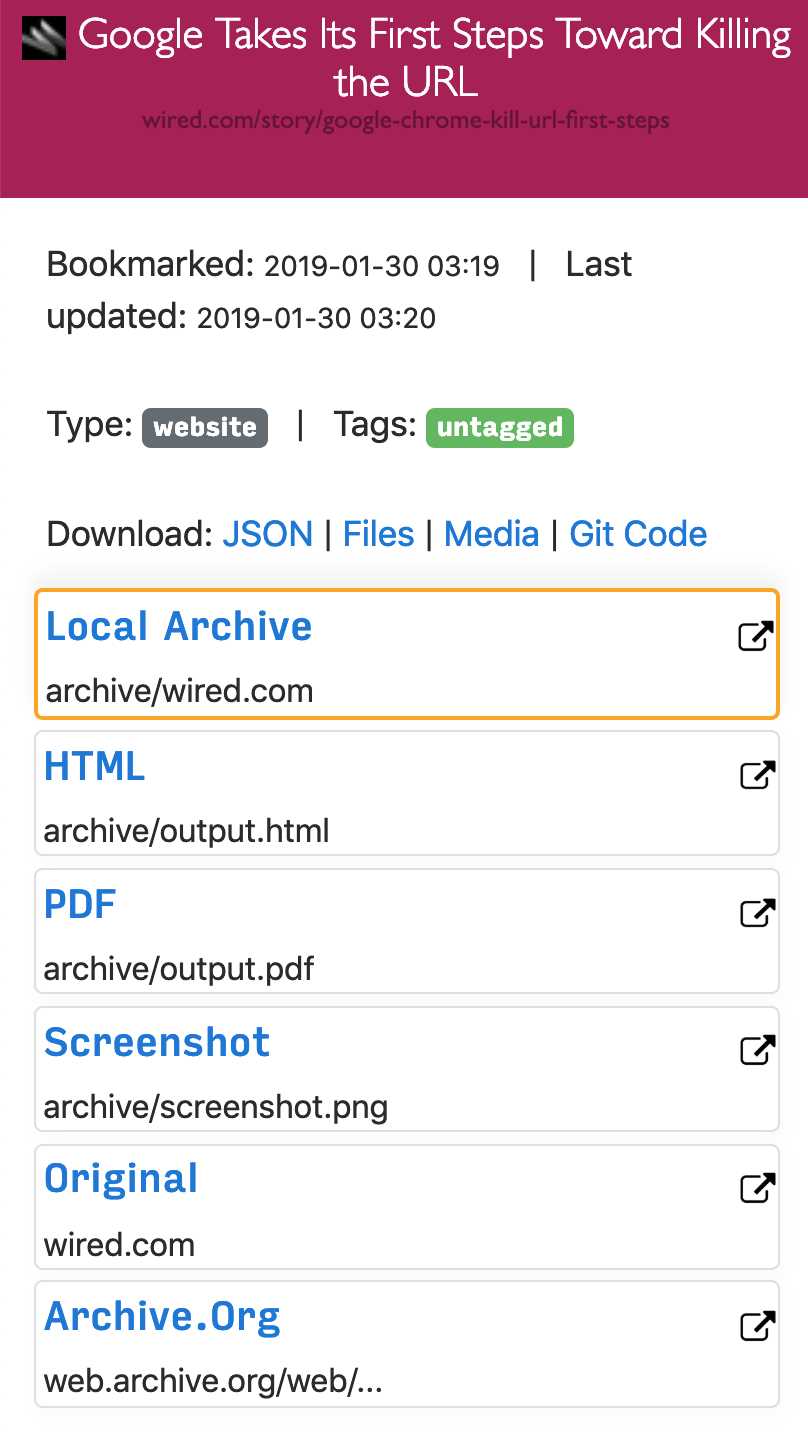
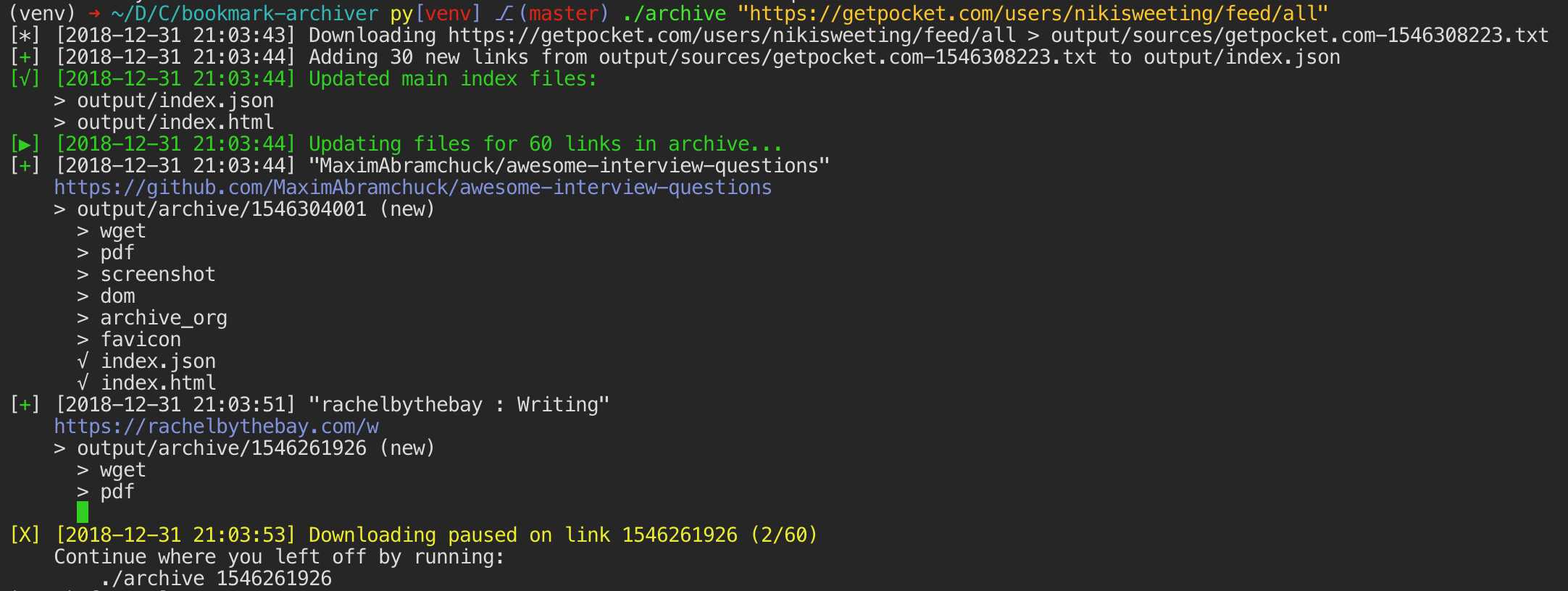
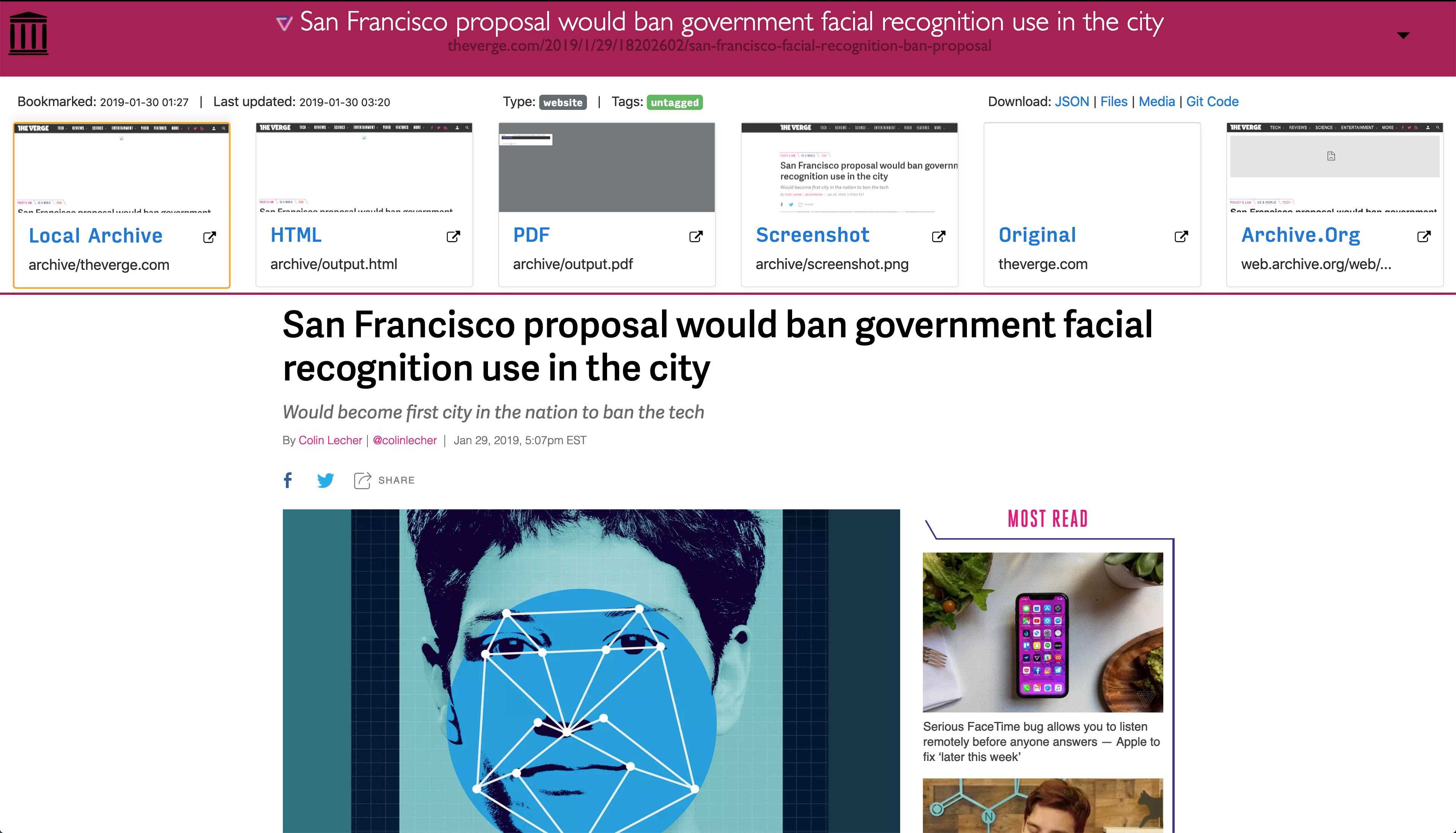
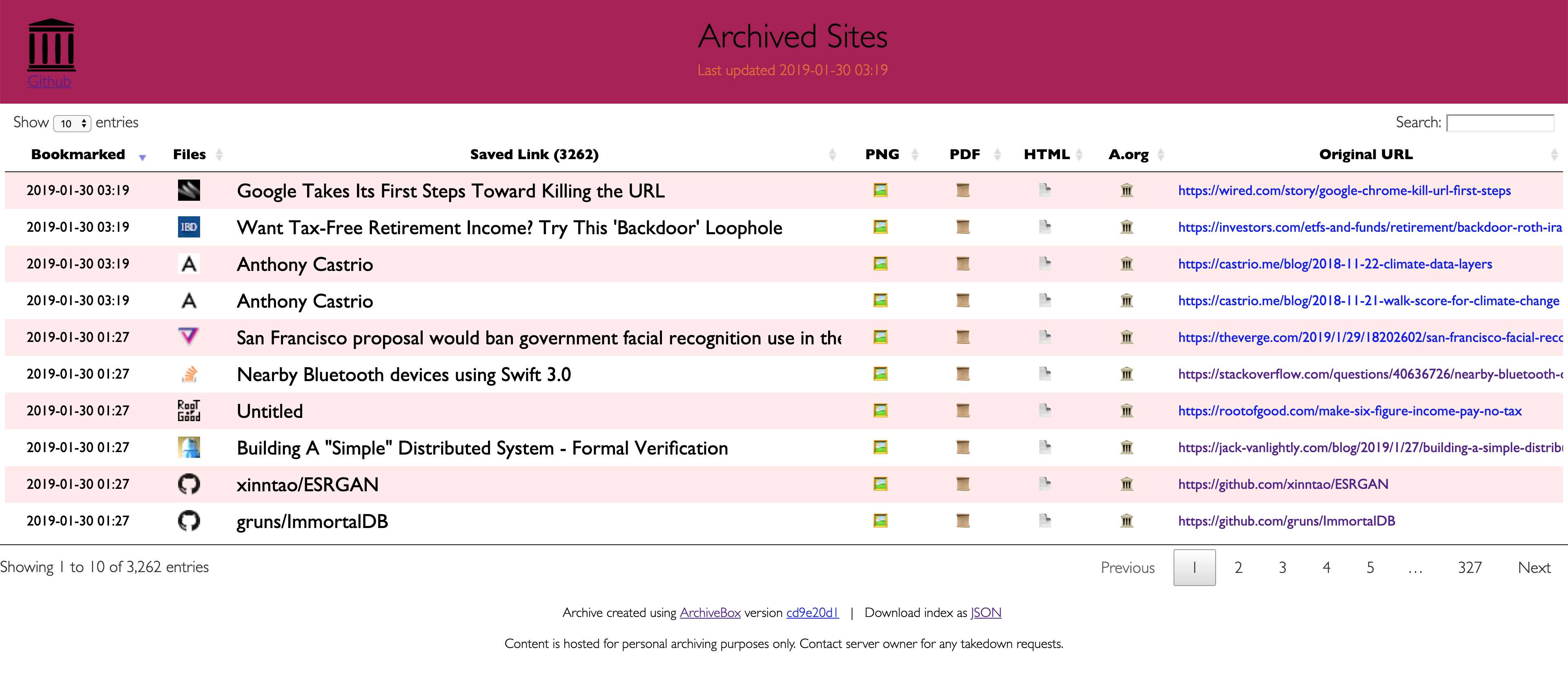
Parce que les sites Web modernes sont compliqués et reposent souvent sur du contenu dynamique, ArchiveBox archive les sites dans plusieurs formats différents au-delà de ce que les services d'archivage publics comme Archive.org et Archive.is sont capables de sauvegarder.ArchiveBox importe une liste d'URL à partir de stdin, d'une URL distante ou d'un fichier, puis ajoute les pages à un dossier d'archive local à l'aide de wget pour créer un clone html consultable, youtube-dl pour extraire le média et une instance complète de Chrome sans tête pour PDF,Capture d'écran et vidages DOM, et plus encore ... L'utilisation de plusieurs méthodes et du navigateur dominant sur le marché pour exécuter JS nous permet de sauvegarder même les sites Web les plus complexes et les plus exigeants dans au moins quelques formats de données à long terme de haute qualité.### Peut importer des liens depuis: - Pocket, Pinboard, Instapaper - RSS, XML, JSON ou listes de texte brut - Historique du navigateur ou signets (Chrome, Firefox, Safari, IE, Opera, et plus) - Shaarli, Delicious, RedditMessages enregistrés, Wallabag, Unmark.it et tout autre texte contenant des liens!### Peut enregistrer ces choses pour chaque site: - favicon.ico` favicon du site - `example.com / page-name.html` clone wget du site, avec .html ajouté s'il n'est pas présent -` sortie.pdf` PDF imprimé du site utilisant chrome sans tête - `screenshot.png` 1440x900 capture d'écran du site utilisant chrome sans tête -` output.html` DOM Dump du HTML après rendu avec chrome sans tête - `archive.org.txt` Un lien vers lesite enregistré sur archive.org - `warc /` pour le fichier warc html + gzippé.gz - `media /` tout mp4, mp3, sous-titres et métadonnées trouvés en utilisant youtube-dl - `git /` clone de n'importe quel référentiel pour les liens github, bitbucket ou gitlab - `index.html` &` index.json`Fichiers d'index HTML et JSON contenant des métadonnées et des détails L'archivage est additif, vous pouvez donc planifier l'exécution régulière de `. / Archive` et insérer de nouveaux liens dans l'index.Tout le contenu enregistré est statique et indexé avec des fichiers JSON, donc il vit pour toujours et est facilement analysable, il ne nécessite aucun back-end toujours en cours d'exécution.
archivebox
Les catégories